
Feb 21, 2024
Disclaimer: This is only meant to serve as a starting point. We recommend doing you own research into each of the LLM’s policies since they may change since this was written.
Leaders incorporating AI into their teams have natural questions around how their data will be used and protected by LLM providers. One of those is around data privacy. Below we summarize the data privacy policies of several commercial LLM providers and how they handle your questions, outputs, and content you provide it.
We take a look at each of the Privacy Policies and Data Usage Policies of OpenAI, Anthropic, Cohere, Google and look into they handle your data in the following categories:
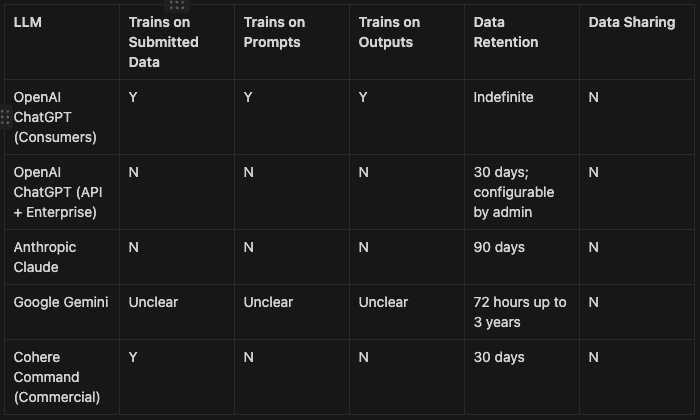
Trains On Data: uses the content you provide to train their LLM
Trains on Prompts: uses the questions or prompts you use during a chat session to train their LLM
Trains on Answers: uses the LLM’s answers to train their LLM
Data Retention: how long they will keep your content for
Data Sharing: whether or not they share with third parties for marketing, advertising or for profit purposes. Almost all providers will share data with relevant law enforcement agencies if required.
Additionally, we prompt the LLM and ask explicitly if they train on submitted content, prompts, or responses.
OpenAI ChatGPT
ChatGPT’s consumer services may use user’s prompts, model’s responses, images, files and other content submitted to ChatGPT to improve their model. However, their API and Enterprise offering does not use content submitted by users nor prompts and responses.
The consumer version of ChatGPT does not specify how long it retains data for, while the Enterprise version’s data retention period is configurable. User’s of their consumer version can opt-out to ensure OpenAI does not use content submitted to them.
OpenAI Enterprise or API usage should be suitable for most Enterprise use cases, and Consumer users can opt-out so OpenAI does not train on your content.
Sources:
Anthropic Claude
Although Anthropic does not explicity train on prompts and outputs from users that interact from Claude, they may train on publicly available data that contains personal information and may train if you give it explicit permission. From this support article:
By default, we will not use your prompts and conversations to train our models. We may use your prompts and conversations to train our models where you have given us explicit permission, such as by submitting feedback, ideas, or suggested improvements you provide to us.
Anthropic does emphasize the importance of privacy. They’ve published their Constitutional AI which outlines the core values that is used to train their LLM, Claude to ensure outputs that are not racist, sexist, homophobic, etc.
Sources:
Google Gemini
Google Gemini’s does not explicitly state whether or not they train on a user’s conversations. However, they do collect conversations, location, feedback, and usage information. You can opt-out of Gemini collecting data on your conversations, however, they will still retain data for 72 hours.
They may retain your conversations for up to 3 years if they’re reviewed by humans. Humans may evaluate conversations to improve their service, and Google provides guidance to not enter anything into Gemini you wouldn’t want a human reviewer to see or Google to use.
Data is not explicitly shared with 3rd parties to service advertising.
User’s may opt-out of Google retaining your conversation history, however, please note they will still retain data for 72 hours:
Sources:
Cohere Command
Cohere’s Command model generally targets enterprises, and so we looked into the policies related to the commercial usage of their models. While Command does not explicitly train on a model’s prompts and responses, they may use them to improve the overall quality of their service.
As far as submitted content (such as when you upload a file), they may add the data to their training dataset.
Sources:

All LLMs either don't train on user input and or allow you to opt-out of training. For enterprise use cases, we think the privacy and data usage policies should suffice.
At OmoAI, we take the security and privacy of your data seriously and similarly don't train on user inputs. You'll always be in control of your data and have the right to understand its usage. For more details on our policies or to request a copy of our security whitepaper, please contact us.
Get a free demo
Leave your email below and we'll be in touch shortly!